|
I am currently a research scientist at Google working primarily on audio and speech generation models. Previously, I worked as a senior research engineer at Qualcomm in the Multimedia RnD team developing on-device models for speech coding. Prior to joining Qualcomm, I was a PhD candidate in the department of ECE at Johns Hopkins University, where I worked on expressive speech resynthesis. At JHU, I've primarily worked on generative modeling of prosody for expressive/emotional speech synthesis. My work lies in the intersection of speech signal processing, statistical modeling, and deep learning. I was advised by Dr. Archana Venkataraman (PI, NSA Lab @ JHU). I did my undergraduate in Electronics and Electrical Engineering at IIT Guwahati where I worked on Keyword spotting for low-resourced languages supervised by Dr. S.R.M Prasanna. During the course of my PhD, I received my masters degree in Applied Math and Statistics at JHU. I've been the receipient of MINDS fellowship award twice for working on the frontiers of machine learning and data science. I have also received ECE graduate fellowship at JHU and DAAD-WISE fellowship award in the past for doing research internship in Germany. Email / CV / Google Scholar / Twitter / Github |

|
|
I'm interested in un/supervised learning, graphical modeling, and signal processing. My research is mainly about understanding and manipulating prosodic information to alter emotion perception in human speech. Here are the papers that I have published in the conferences/journals or are currently under review: |
|
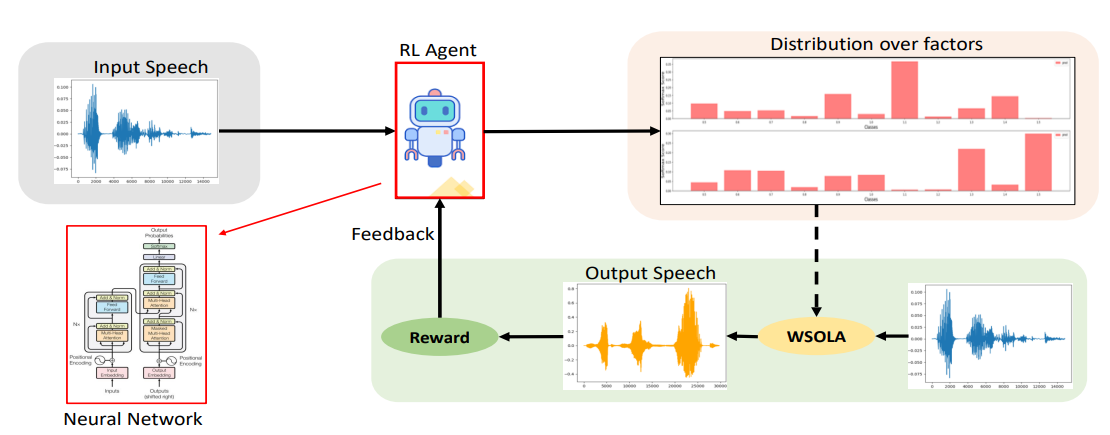
Ravi Shankar, Archana Venkataraman arXiv Preprint: 2408.01892 Paper In this work, we propose the first method to modify the prosodic features of a given speech signal using actor-critic reinforcement learning strategy. Our approach uses a Bayesian framework to identify contiguous segments of importance that links segments of the given utterances to perception of emotions in humans. |
|
Ravi Shankar Johns Hopkins University Thesis In this thesis, we devise different ways of learning prosody modeling techniques to inject emotion into neutral speech. We develop supervised algorithms for F0, energy and rhythm modification followed by unsupervised approaches that combines probabilistic graphical modeling with neural network as density function. |
|
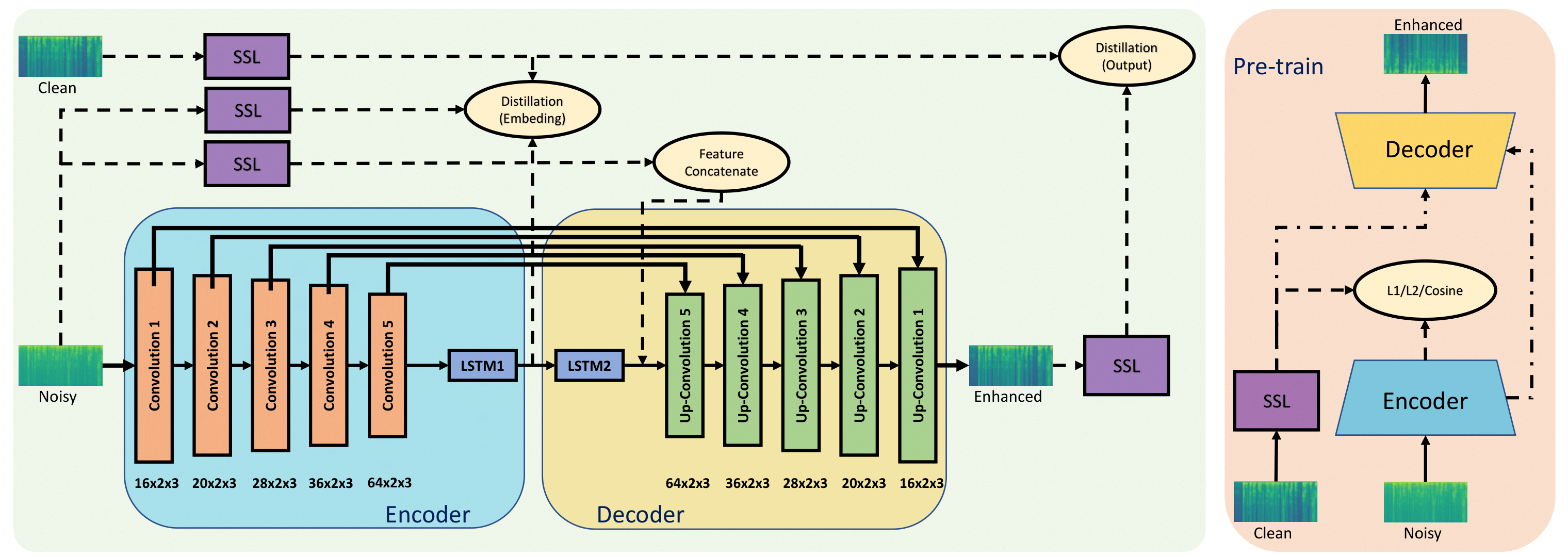
Ravi Shankar, Ke Tan, Buye Xu, Anurag Kumar ICASSP 2024 Paper In this work, we proposed different ways of using Wav2Vec2 embeddings for single channel speech enhancement. Our study shows that in a constrained (low-memory/poor SNR/causality) settings, SSL embeddings fail to provide helpful information to improve enhancement task. |

|
Ravi Shankar, Archana Venkataraman ISCA SSW12, 2023 code / Paper We propose the first method to adaptively modify the duration of a given speech signal. Our approach uses a Bayesian framework to define a latent attention map that links frames of the input and target utterances. |
|
Ravi Shankar, Hsi-Wei Hsieh, Nicolas Charon, Archana Venkataraman IEEE/ACM Transactions on Audio, Speech and Language Processing, 2022 code / arXiv In this work, we extensively study the cycle consistency loss in the context of Cycle-GAN model. We identify some of its major shortcomings and propose a new loss function to address the pitfalls. |
|
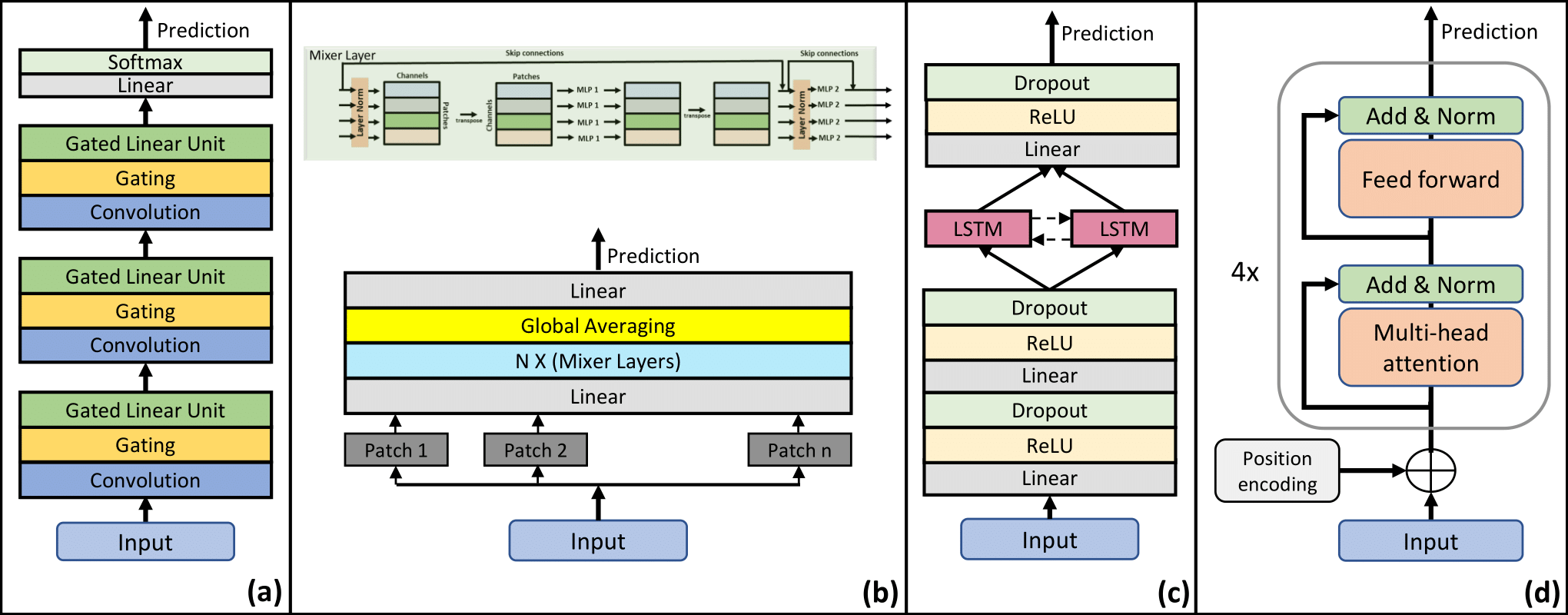
Ravi Shankar, Abdouh Harouna, Arjun Somayazulu, Archana Venkataraman arXiv We comprehensively study different types of data augmentation procedures in the context of speech emotion recognition. Our study spans multiple neural architectures and datasets for an unbiased comparison. |
|
Ravi Shankar, Jacob Sager, Archana Venkataraman Interspeech, 2020 code / arXiv Improved Cycle-GAN by using KL divergence penalty on the conditional density in addition to cycle-consitency loss. |

|
Ravi Shankar, Hsi-Wei Hsieh, Nicolas Charon, Archana Venkataraman Interspeech, 2020 code / arXiv A chained model using latent variable regularization to mediate conversion from one emotion to another in speech. |
|
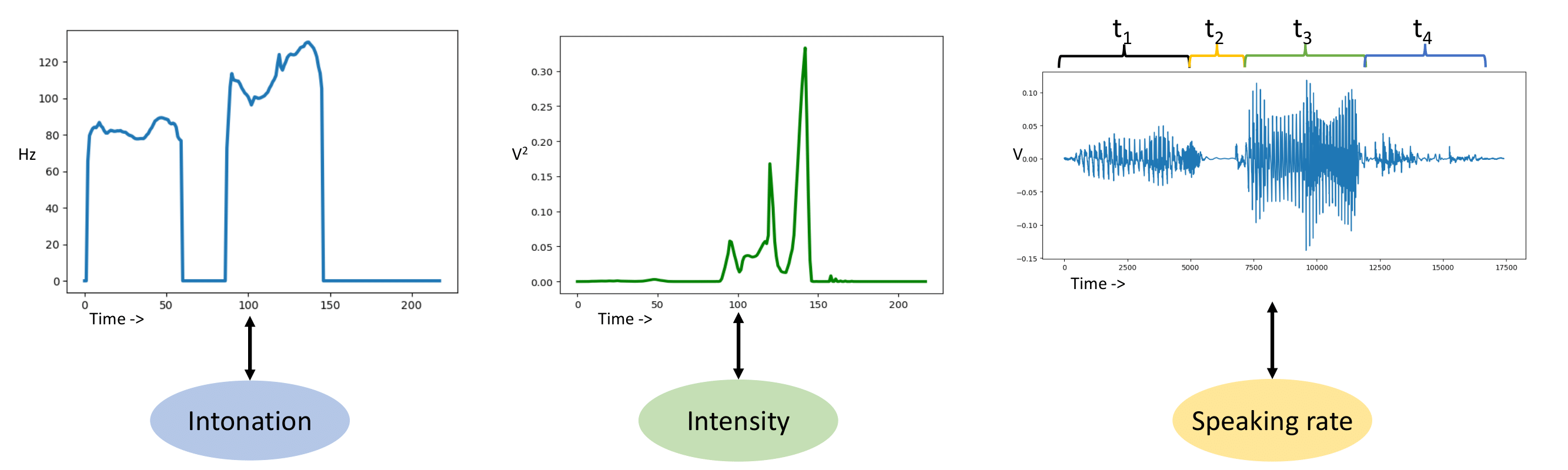
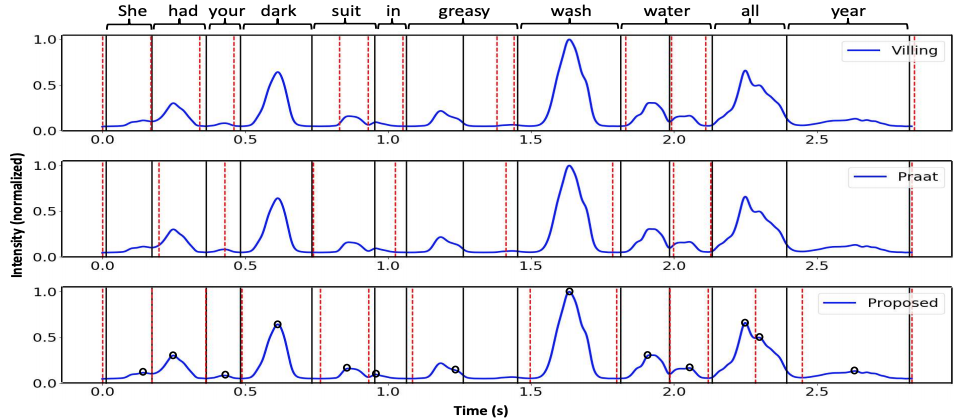
Ravi Shankar, Archana Venkataraman Interspeech, 2019 We use the vowel/consonant peak identification in the loudness profile of speech to carry out syllable segmentation. |

|
Jacob Sager, Ravi Shankar, Jacob Reinhold, Archana Venkataraman Interspeech, 2019 (Oral) dataset VESUS corpus contains 250 phrases spoken by 10 different actors in 5 emotion categories. The objective is to study factors underlying emotion perception in a lexically controlled environment. |
|
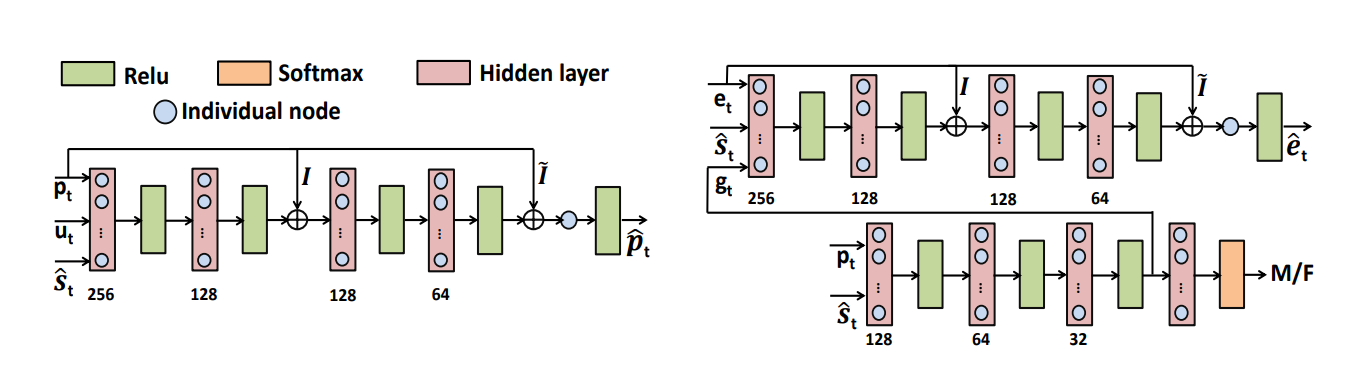
Ravi Shankar, Jacob Sager, Archana Venkataraman Interspeech, 2019 (Oral) code We propose a perturbation model for F0 and energy prediction using highway network. The model is trained to maximize the likelihood of error in an EM framework. |
|
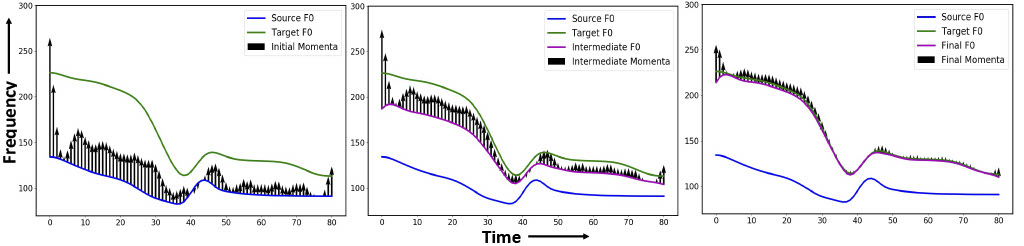
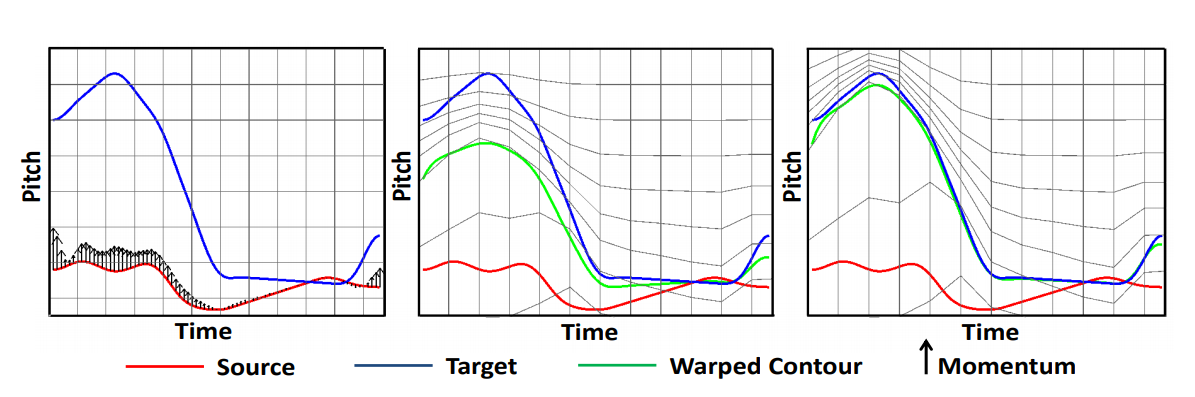
Ravi Shankar, Hsi-Wei Hsieh, Nicolas Charon, Archana Venkataraman Interspeech, 2019 code We use diffeomorphic registration to model the target emotion F0 contour. It serves as a regularization technique for better target F0 range approximation. |

|
Ravi Shankar, Vikram C.M., S.R.M Prasanna Interspeech, 2018 (Oral) In this paper, we propose a randomized DTW method coupled with convolutional network to identify presence/absence of a keyword. |

|
Ravi Shankar, Arpit Jain, Deepak K.T., Vikram C.M., S.R.M Prasanna NCC, 2016 We propose a sequence of morphological operation to refine the DTW matrix for easier keyword spotting. |
|
|
|
Teaching Assistant, Probabilistic Machine Learning (EN.520.651) Fall 2021, 2022 |
|
 |
Reviewer, ICML 2024 |
 |
Reviewer, NeuRips 2022, 2023 |
 |
Reviewer, UAI 2023 |
 |
Reviewer, ICLR 2022, 2024 |
 |
Reviewer, Interspeech 2021, 2022, 2023, 2024 |
 |
Reviewer, CISS 2021 |
|
This website's template has been taken from here: source code. |